
Regex or Regular Expression is a super powerful way for searching in text when you don't know exactly what you want to find, but have partial information.
To understand why this is useful, lets take an example. You are running a business of selling subscriptions to Microsoft Office 365 Enterprise to other Businesses. You have a Contact Sales Form on your Website. Something like this
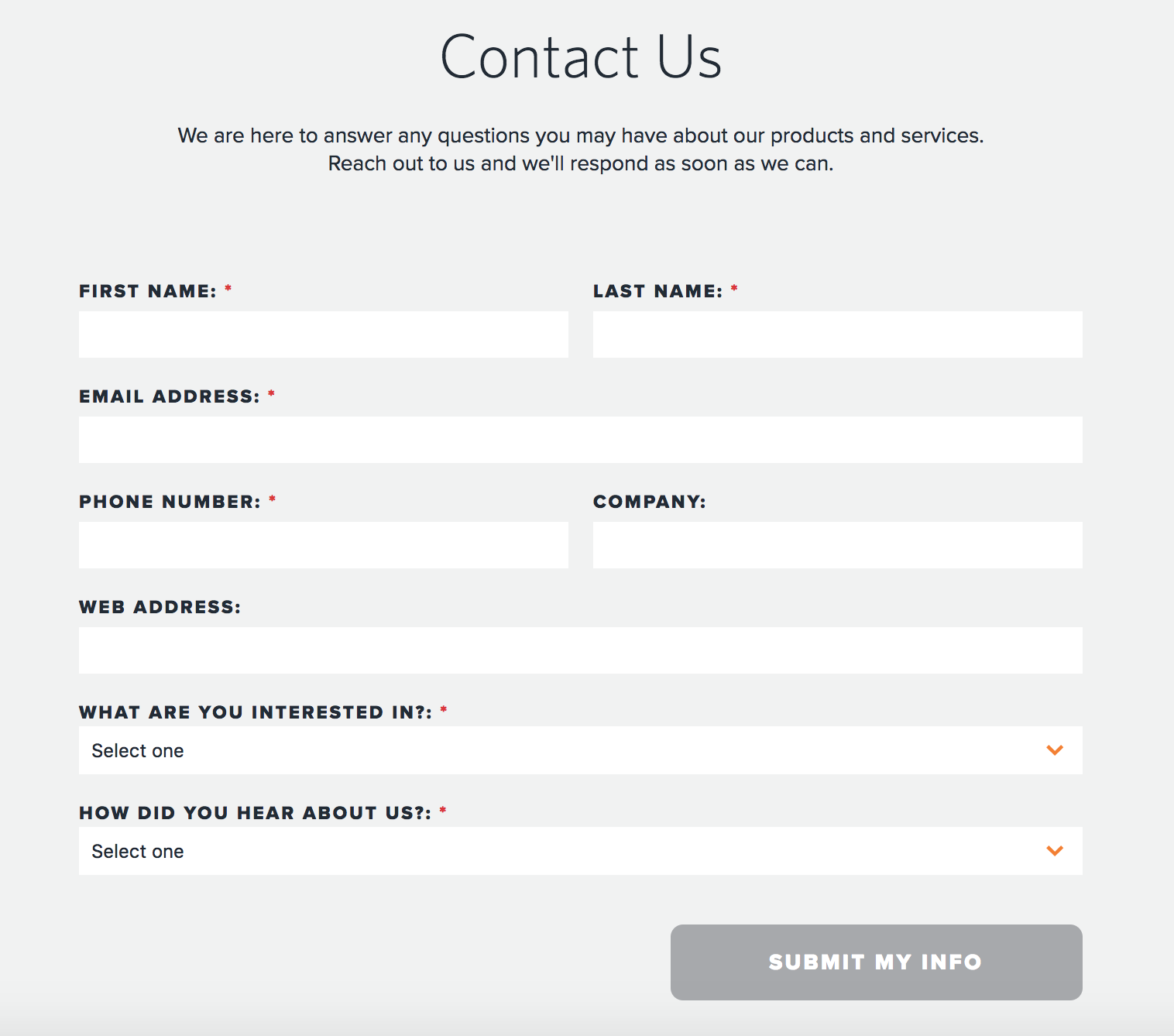
Your Marketing team had organized a great promotion drive and leads are pouring up. You now have a couple thousand forms to go through.
Your Sales team, barely 5 individuals, will take weeks to go through every one of those leads. They have to mail them, wait for them to reply, pitch your product's USP and convince them to at least try your free trial. Research has shown that the slower you respond to a lead, the more likely it will go cold, i.e. they won't be interested in buying your product.
The task is now clear. You need to whittle down the thousands of leads you have to a more manageable 100-200. Now That, will be achievable by your team. Who knows, you might finally be able to get a bigger team from the business generated by these leads. In this case, there is reasonably reliable way to filter out the leads that are more likely to be converted.
Emails with a custom domain, like @verizon.com, @snapchat.com , @bloomberg.com, etc are more likely to be owned by individuals from well established companies rather than those from @gmail.com, @live.com, @yahoo.com. This is because there is a cost to setting up an email address with custom domains like these unlike those from free email providers like google and yahoo.
Solving this Problem
This is where we finally reach the point of this blog. To filter out all the emails from public domains, to use a find and replace algorithm would require a cumbersome process somewhat like this:
- Loop through the list of known free email providers =>
known_domain- Loop through list of
lead_emails=>email- Check if
known_domainis present inemail- Remove
emailfromlead_emails
- Remove
- Check if
- Loop through list of
- The resultant array
lead_emailsis the list of non-free(custom) domains.
To Illustrate the difference, the following demo can help.
The check-boxes on the top right show the two methods:
- Find and Replace: The way you would do this with find and replace.
- Regex: The concise way
You can go through each step by clicking around on the buttons in the button-right.
As you see, the code becomes a magnitude simpler, from 4 lines to a one liner. This demo focuses one of the simpler uses. Some other harder problems that becomes easier, or rather possible, to solve with Regex are:
Example 1: Checking if an email is valid.
For example, karen.global@james is not a valid email. This is because james is not a valid TLD(Top Level Domain). Encoding this information in a Regex would be like the domain match the above demo shows. For doing this without regex would at best cause verbose code. It would likely devolve into a mess of if statements otherwise.
Example 2: HTML Parsing
In fact, most parsing tasks would be a breeze with regex. Finding HTML tags with contents would be easily achieved by this regular expression <(\w+).*>(.*?)<\/\1>. Work with the regex at https://regex101.com/r/HHIiuW/2.
Example 3: Processing Shell output
I often use Linux commands to get information about Files, or going through Log files to debug issues.
To find the exact location of the issue, we can use the command grep to get the line where the matching string exists.
There is a nifty flag -E that enables regex matching. This makes life so much simpler.
As a common debugging scenario, if your distributed application has error codes like [ERROR:location1:program1.34], [ERROR:location2:program2.34], etc. You want to know how many errors program2 has, across all locations.
You might be tempted to search based on :program2. But this will clash with other levels of error reporting like INFO and WARN. A better choice would be the regex [ERROR\:.*?:program2 .You can play with this example at https://regex101.com/r/TFxUGz/1.
Parting Thoughts
Every developer must have a preliminary grasp on the common regex symbols and how to use regex in their chosen language as well as the shell. This will save days of time spent reinventing searching in the future.
Resources
Regex101 is a cool website that i use often to create/debug tricky expressions
Sed.js.org is a similar testing website to test out sed command that will do your bidding. Sed or Stream Editor is useful for replacing text on huge files which crash your editor when you open them, for example logs. It can also help post-process any piped output in shell
Mozilla Resource on Regex is quite useful to extensively learn Regex.
Regexone is an interactive approach to learn Regex. As they say, we learn
Excellent example for Regex Good Content
Really good blog
Very precise, thanks for sharing.